Classification(Auto Pilot)
The Classification algorithm is a Supervised Learning technique that is used to identify the category of new observations on the basis of training data. In Classification, a program learns from the given dataset or observations and then classifies new observation into a number of classes or groups. Such as, Yes or No, 0 or 1, Spam or Not Spam, cat or dog, etc. Classes can be called as targets/labels or categories. Below is the view that comes up when you click on Classification procesor.
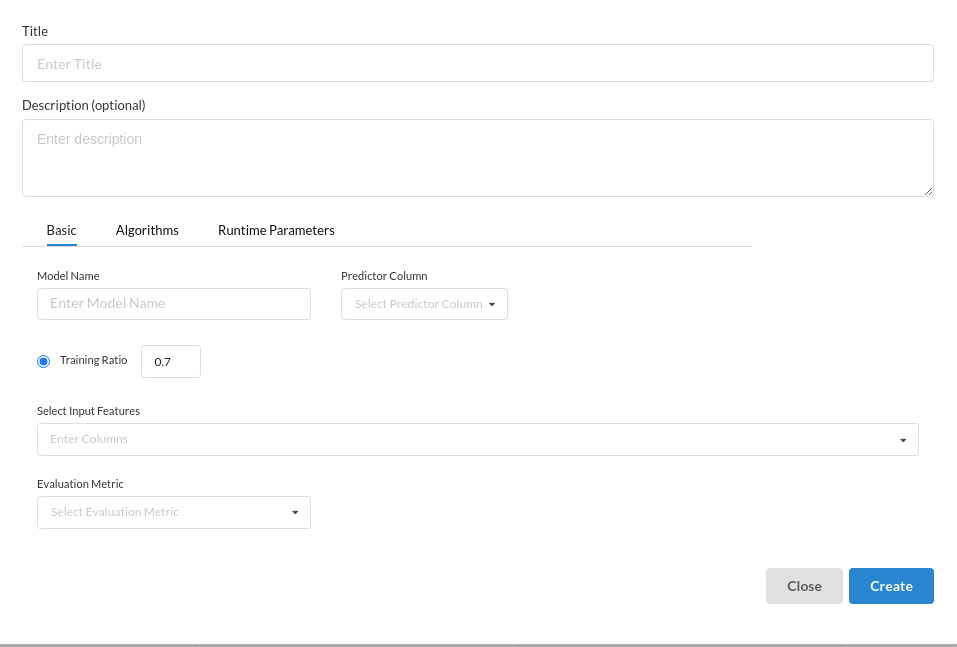
The sub view under classification are as below:
- Enter the Title of the step. Usually suggested to keep this short .
- Optionally Jot down everything you want to do inside of this processor under Description.
- Under the Basic Configuration view you will see :
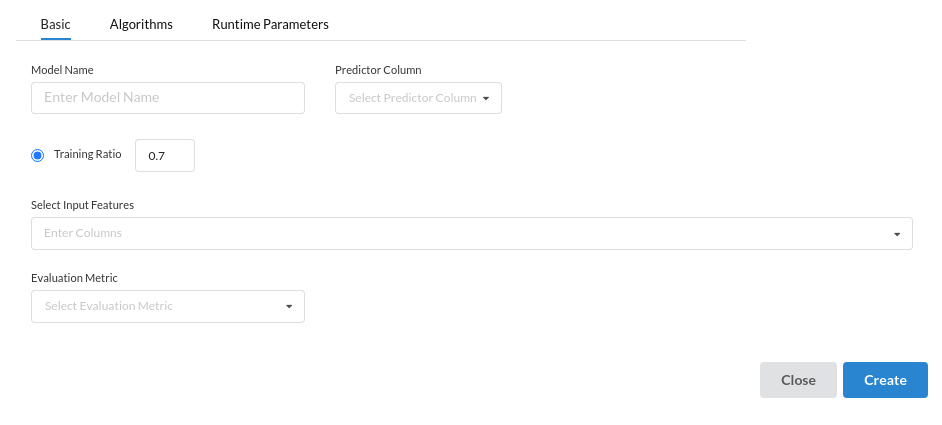
Sub views under Basic Configurations are :
- Model Name: Enter the Model you want to build . For example : Credit Fraudulant classification
- Predictor Column : Choose a column from the drop down which is going to be your dependant column. i.e the column which is going to be predicted .
- Training Ratio : Split your dataset by the training and test ratio. If your training ratio is 0.5 then you are configuring 50% of the date for training and 50% of the dataset for testing.
- Select Input Features : choose your Independant Variables from the drop down that comes when you click on select input features.
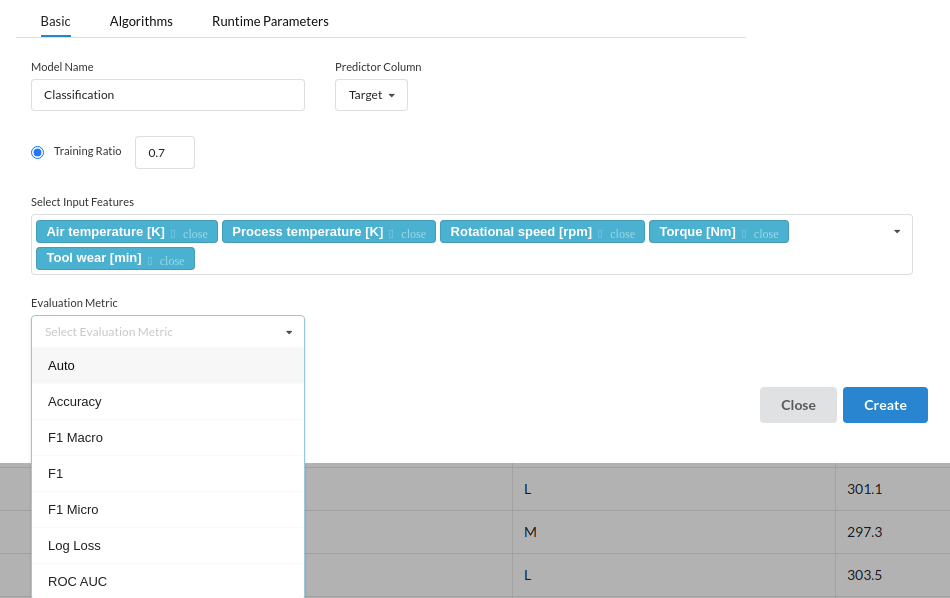
- Evaluation Metric: Since this is a classification processor , you will get the relevant metrics used for classification.
Supported Metrics for Classification are as follows :
- Auto : If chosen Auto, the system will by default take the metric to be accuracy
- Accuracy
- F1 Macro
- F1
- F1 Micro
- Log Loss
- ROC AUC
- Under Algorithms the view you will see all the algorithms suported by Xceed. You can choose or unselect any algorithm you don't want.
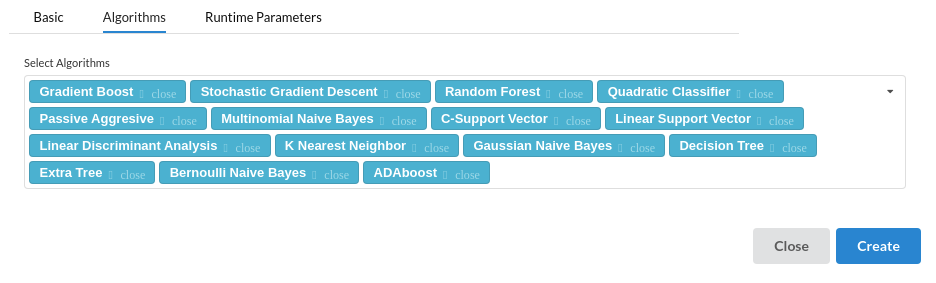
list of algorithms supported are :
- Gradient Boosting
- Stochastic Gradient Descent
- Random Forest
- Quadratic Classifier
- Passive Aggresive
- Multinomial Naive Bayes
- C-support Vector
- Linear Support Vector
- Linear Discriminant Analysis
- K Nearest Neighbor
- Gaussian Naive Bayes
- Decision Tree
- Extra Tree
- Bernoulli Naive Bayes
- ADA boost
- Under RunTime Parameters you will see :
- Time Per Algorithm : Allocate the number of seconds you want a model to be trained. Suppose you chose 3 algorithms, you and the allocated 180 secs then your time per algorithm is 180 x 3
- No. Of Iterations : fill out how many times you want an algorithm to be trained . If you give 2 iterations, your run time for the whole model building is (180 x 3) x 2
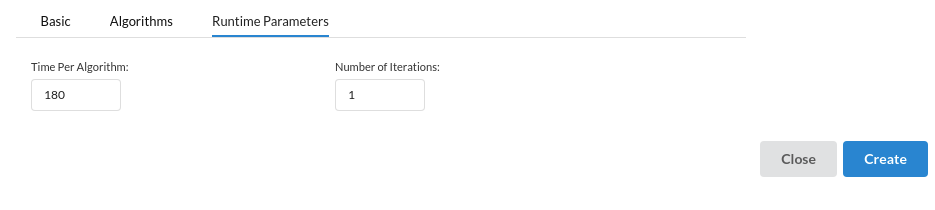
- After the whole view is filled click on Create to start building the model .