Xceed Analytics - Engine Independance
Xceed Analytics comes with great capabilities such as NO-CODE workflow designer , Data Catalogue , Data Connectors and a lot of ML loaded transforms which can help all the designations across the data teams collaborate and become efficient. While there are a lot of features being packed, The biggest capability of Xceed Analytics is that it can work on multiple compute engines. That is, Xceed Analytics supports working on Pandas , PySpark, DuckDb , Dask and many more to come.
Engine Independance
The basic idea of Engine Independance is that user can work on any compute engine without having to understand the architecture underneath the engine. Compute Engines like Pandas , Pyspark, Dask require a lot architectural knowledge to actually use them proficiently but Xceed Analytics makes sure all that is hidden for you and let you build your pipelines effortlessly.
Engine Independance Provides certain benefits:
- Ensures application portability irrespective of the engine.
- Develop the pipeline on one of the engines for. ex Pandas (using sample data) and then deploy the same on a different engine. for. ex. Spark or Dask.
- Unify Data Engineering and Data Science Workloads
- Work on multiple engines with little to no knowledge of distribution frameworks.
- All these can be done using the NO-CODE workflow designer
Configuration
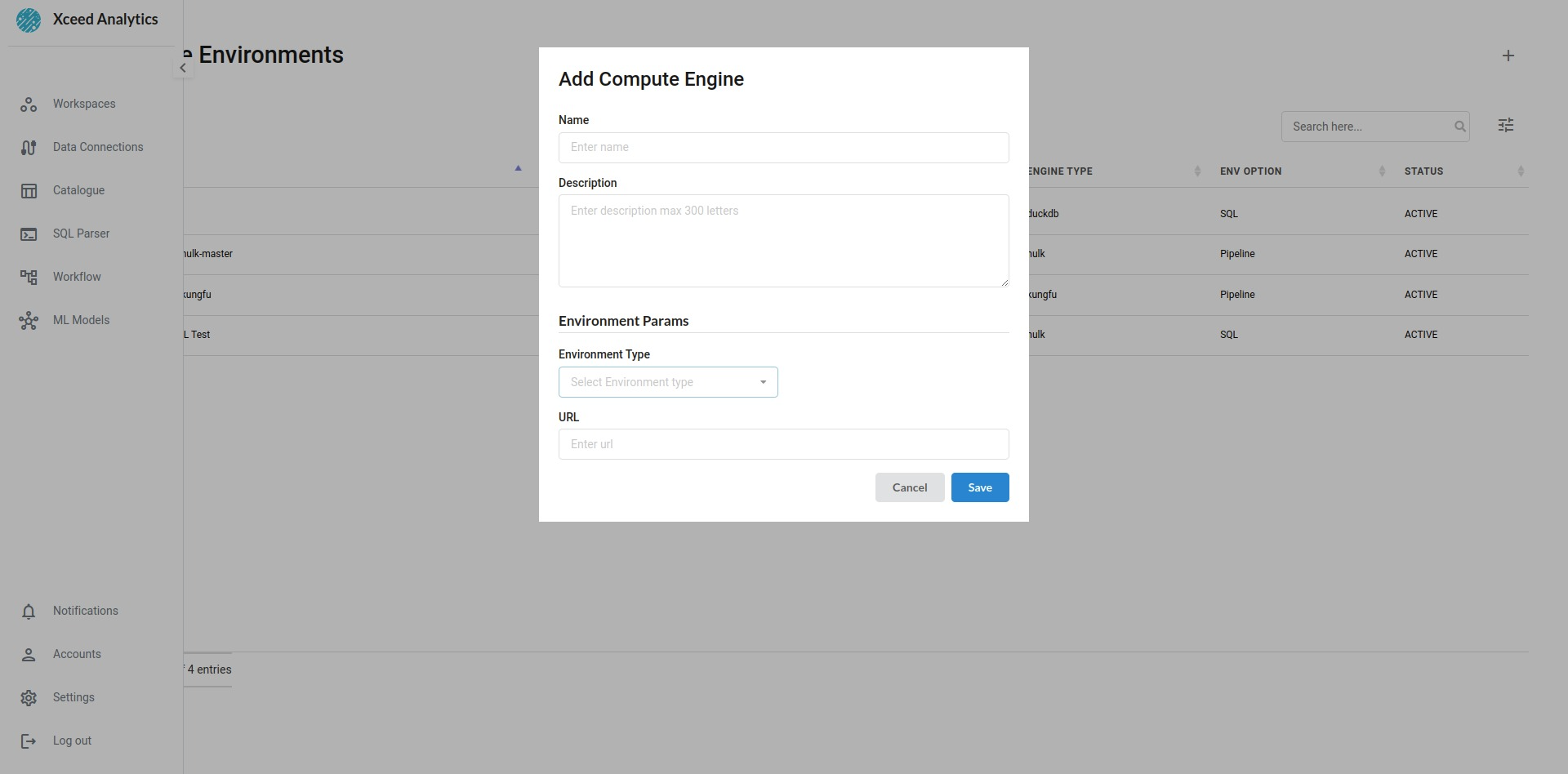
Configure one of the supported engines under Admin Settings by giving a name for the engine and it's purpose and other required fields
The view under Admin Settings for configuring an engine would look like the one below