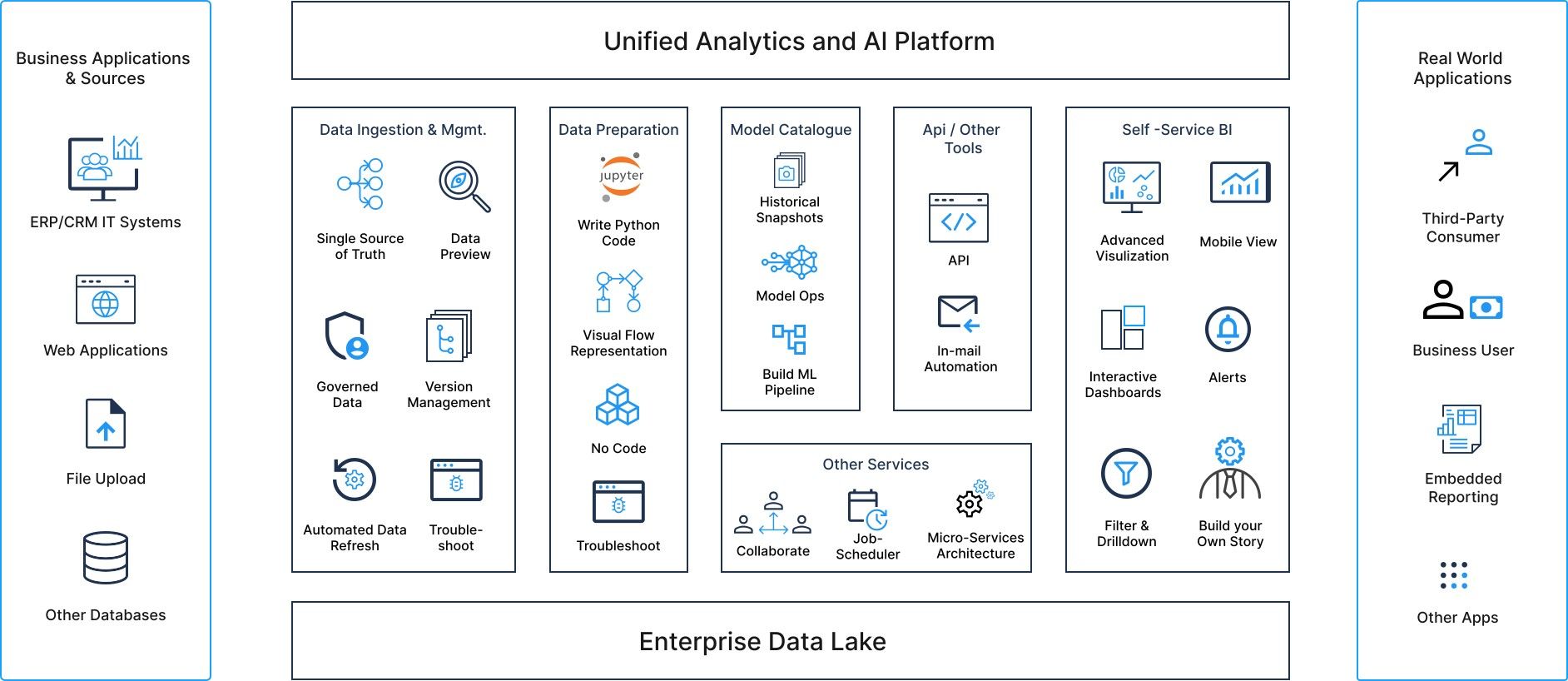
Is Unified Data and AI Platform Answer to Success of Data Science Projects?
Background
More and more enterprises are embracing data science as a function and a capability. But the reality is many of them have not been able to consistently derive business value from their investments in big data, artificial intelligence, and machine learning. However, A surprising percentage of businesses fail to obtain meaningful ROI from their data science projects. Enumerous articles have been written on failure rate, root causes and how do we improve the success of such projects.
A few statistics on Data Science Project Failures
-
Failure rate of 85% was reported by a Gartner Inc. analyst back in 2017.
-
87% was reported by VentureBeat in 2019 and
-
85.4% was reported by Forbes in 2020.
The dichotomy of those numbers is that the outcome that enterprises are witnessing despite the breakthroughs in data science and machine learning, tons of wonderful articles and videos sharing experiences, enumerous number of open source/commercial libraries/tools.
Moreover, evidence suggests that the gap is widening between organizations successfully gaining value from data science and those struggling to do so. So what are the top reasons preventing data science projects from succeeding. Reasons for failure can be further categorized broadly as below:
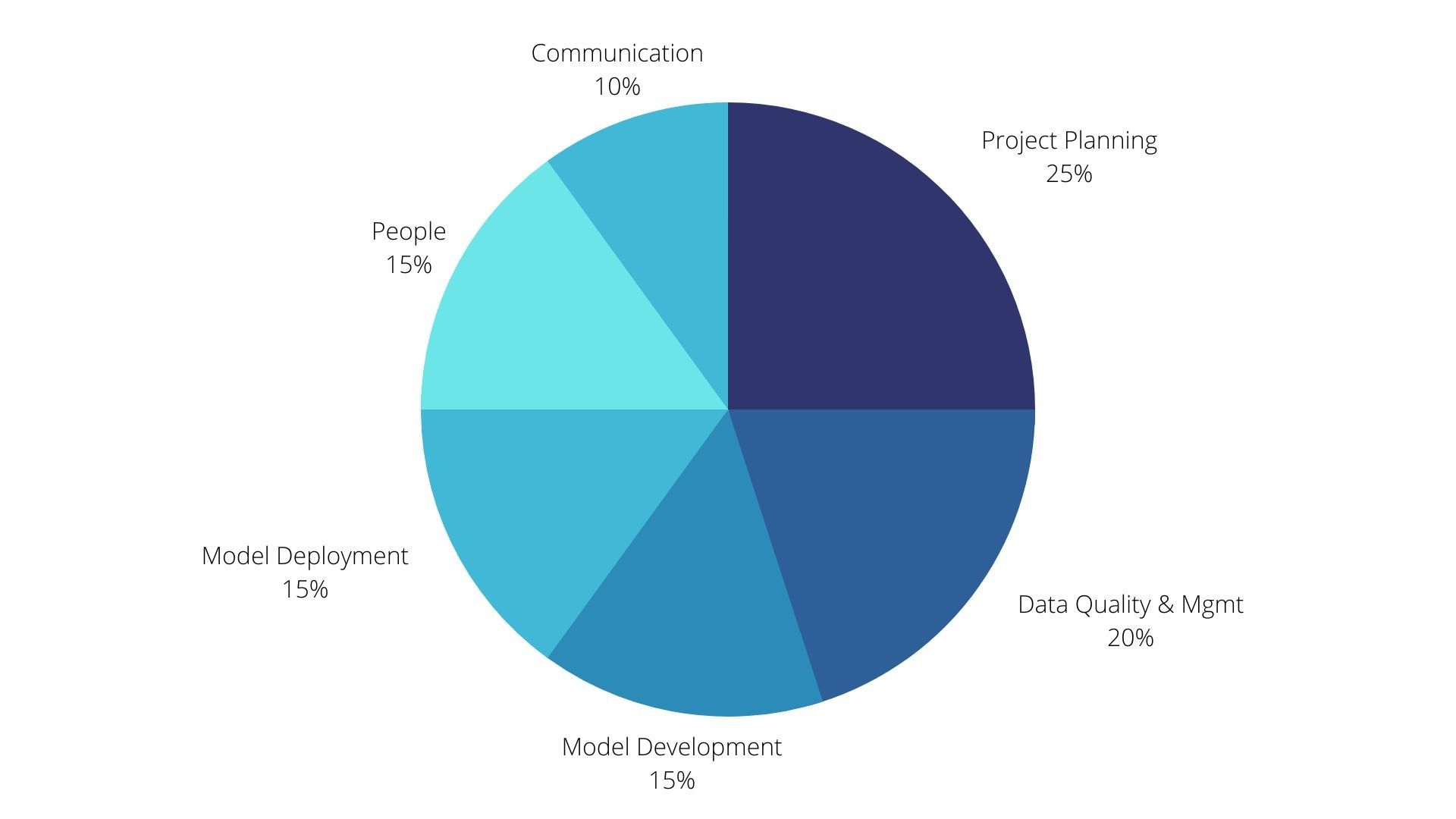
Project Planning & Costs
-
Lack of clearly articulated business problem and documentation of it.
-
Lack of upfront articulation of business value/outcome expected from the project and therefore prioritization.
-
Lack of stackholder involvement and communication plan with them right from the beginning.
-
Unstated/Undefined deployment planning as part of project planning.
-
Not the right use case.
-
Cost of Experimentation often prohibitive and inhibits ROI.
People
-
Data Science & ML Skill Shortage.
-
Data Scientists often not trained in design patterns as programmers leads to sub-optimal , un-performant and short-lived model modeling code.
-
Data Scientists often interested in exploration and experimentation and stay away from productionizing efforts.
-
Lack of Cognizance that Data Science Model Training & Deployment often follows all the processes of a software project deployment, versioning, testing and iterations for fixing the quality. Organisation of the team often doesn’t constitute experts or trained staff who have understanding of the development, testing and CI/CD pipeline.
-
Lack/Absence of Data Culture/Maturity within the organisation.
Data Management & Data Quality Process/Tools
-
Siloed data in different repos and no clear plan of how this will work during successive iteration.
-
Insufficient or Unavailable data
-
Poor Quality of data
-
Unregulated/Unnoticed changes to schema and data distributions
Modelling
-
Model training/Experimentation often done outside of the production environment leads to completely redoing model training once the software engineers take it over for deployment
-
Lack of feedback loop from model deployment to model learning phase leads to deterioration.
-
Interpretability of the model compromised for model accuracy
-
Model Trustability with the business stackholder and many a times an unknown fear of a negative impact of model on business. Instances/Articles like Zillow substantiate potential damage that a model can do.
-
Lack of Trust/Apprehension (founded/unfounded) on model among business stackholder often leads to model not making it to deployment.
-
Lack of process for historical saving model artifacts, reason for changes etc over time leads to poor auditablity and lends itself to lack of trust.
Communication
- Lack of coordination between business and data science teams on results/outcomes/changes.
Deployment
-
No real time auditing and logging of model results in actual deployment
-
No checks and bounds for data and concept drift and feeding the performance into the data science team and business stackholder.
-
Integration with Online Transaction systems and applications which often form the consumption layer often not planned. This leads to poor adoption of models.
While there are myriads of problems for a model to succeed through deployment and longitivity of such a deployment during the course of production usage, At Cynepia, we believe that Unified Data and AI Automation Platform and No Code Data Science and Continuous Productionization can significantly improve the chances of success modeling use cases by addressing many of the challenges above.
Solution
An End-to-End No Code/Low Code Data Science platform brings significant advantages, as listed below and can significantly address many of the data science pitfalls listed above. Unified Platform acts as a single hub for all your data, models and stackholder ensuring communication between business and data science team is near realtime ,both during the project execution and model monitoring phase.
Integrated Data Catalog and Data Pipelines ensure that data schema changes are notified and always available to the data science team, to understand if there are any upstream data quality changes.
Discovery of newer features/datasets published by data engineering team further helps create synergy on finding new useful features.
Visual Model Building helps data scientists focus on business outcome and experimentation than learning design patterns thereby improving longitivity of modeling effort.
Visual Data Exploration (EDA) and Model Interpretation enables faster socializing of data/model changes before deployment
Model Catalog further ensures model revisions are stored.
One click Model Deployment enables faster deployment of approved models to production.
Model Monitoring further helps track data/concept drift in running phase and helping ensure models are retrained.
Conclusion
End to End No/Low Code Unified Data and AI Platform offers a promising alternative to reducing data science project failures both by streamlining projects from implementation to production and monitoring as well as significantly reducing effort needed to upkeep code and data over time. Bringing all stack holders on the same page can reduce apprehensions and enhance trust among business stackholders by enhancing collaboration.